It’s not just a hobby. It’s the best IT training program money can’t buy.
If you work in IT, or you’re thinking about getting into it, someone has probably told you to “get a homelab.” Maybe you nodded and moved on, thinking it sounded like a lot of effort for something you’d use twice. I get it. But I’m here to make the case that a homelab is one of the most valuable things you can invest in — not just for learning, but for your career, your wallet, and your daily life at home.
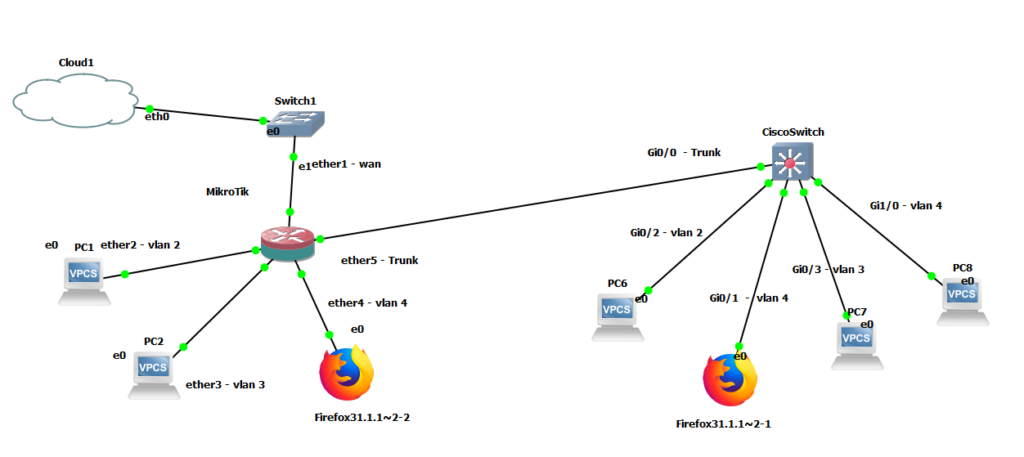
I’ve been running mine for years. It started small and has grown into a three-node Proxmox cluster, a full self-hosted services stack, a home NVR system, and the foundation for a serious side income. None of that happened overnight, but all of it started with the same thing: a spare machine and a willingness to break things.
And you don’t need to start big. A Lenovo mini PC or an HP EliteDesk — 8th generation or newer — can be found used for very little money. They’re compact, power-efficient, and more than capable of running a real homelab. One of those machines, set up properly, will put you on a path of professional growth that no certification alone can replicate.
Here’s why you should do the same.
You Learn by Breaking Things, Not Reading About Them
There is no certification, no course, and no amount of documentation that teaches you the way a 2am crash does.
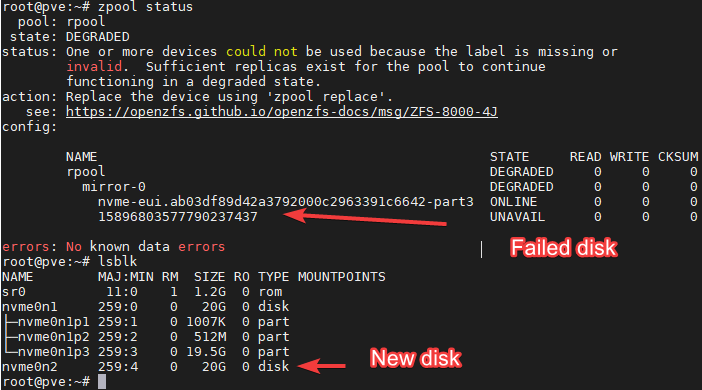
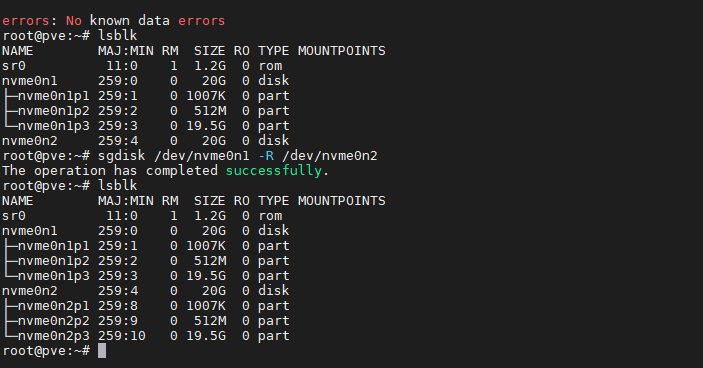
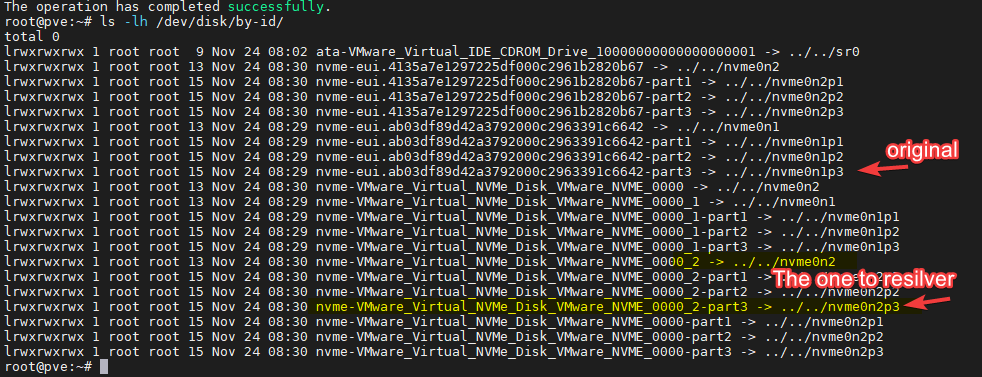
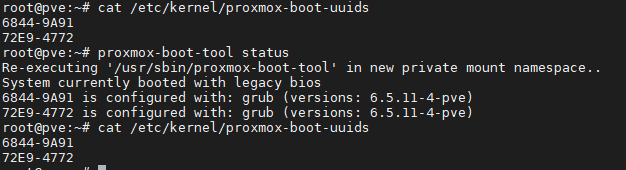
When my backup script left a stale NFS mount that froze an entire server for 76 minutes, I learned more about how the Linux kernel handles NFS retries than I ever would have from a book. When my network card started crashing overnight and I discovered that ICMP keeps responding even during a TX queue hang — completely defeating ping-based monitoring — that’s the kind of nuance that only comes from real experience.
But it goes well beyond server crashes. Running a homelab naturally pulls you into territory you wouldn’t otherwise explore:
- You start setting up a firewall and end up understanding stateful packet inspection, connection tracking, and why rule order matters.
- You want remote access, so you run your own VPN server — and suddenly WireGuard, certificates, and key management aren’t abstract concepts anymore.
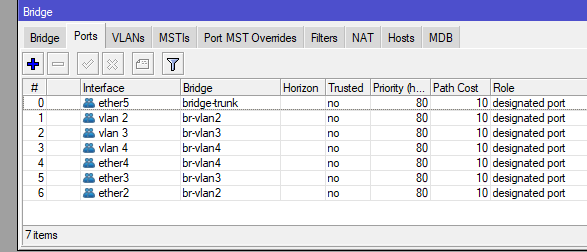
- You have IoT devices you don’t fully trust, so you learn about VLANs and network segmentation to keep them isolated from the rest of your network.
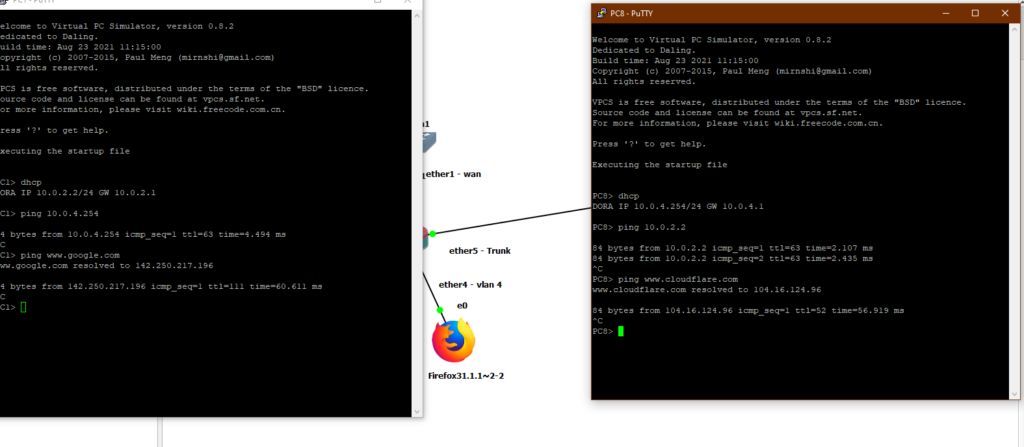
- You deploy a few services and realize you need proper DNS — and then you’re deep into split-horizon DNS, local resolvers, and why you should never rely on your ISP’s nameservers.
- You want HTTPS on your internal services, so you learn about TLS certificates, Let’s Encrypt, DNS challenges, and wildcard certs.
- You spend enough time in the terminal that Linux stops being intimidating — and one day you realize you’ve made the switch from Windows entirely, not because you forced it, but because it just started making more sense.
Every failure in a homelab is a controlled failure. Nothing is on fire. No customer is affected. No boss is watching. You have the freedom to dig deep, understand what actually went wrong, and fix it properly. That knowledge sticks in a way that reading never does.
It Directly Benefits Your Career
I’m not going to name my employer, but I’ll tell you this: the skills I’ve built in my homelab have made me measurably better at my job. Troubleshooting approaches, understanding how systems fail, knowing what questions to ask — all of it comes from hours spent in my own environment where I had no one to call and no escalation path.
The homelab is also where I stay sharp on technologies I don’t use daily at work. Kubernetes, Ansible, DNS architecture, reverse proxies, certificate management — I can speak to all of these because I’ve actually run them, broken them, and fixed them.
If you’re preparing for a job interview or a certification, there’s no substitute. Talking through a lab scenario you actually built is infinitely more convincing than reciting theory. Recruiters and technical interviewers can tell the difference immediately.
It Creates Real Economic Value
This one surprises people, but the skills you develop in a homelab are directly marketable — and I’ve seen it happen firsthand with people I know.
Friends of mine who run homelabs have turned that knowledge into a genuine edge when working with small businesses and SMEs. Instead of recommending expensive proprietary solutions, they can deploy cost-effective, FOSS-based infrastructure that does the same job — sometimes better — at a fraction of the cost. A proper Proxmox cluster, self-hosted DNS, a WireGuard VPN, a mail stack, a reverse proxy with proper TLS — all of this can be set up and maintained by someone with homelab experience, and smaller clients who can’t afford enterprise vendors are hungry for exactly that.
The homelab is where you build the muscle memory to do this confidently. You’ve already broken and fixed these things in your own environment. When a client’s server goes down at an inconvenient hour, you’re not googling basic commands — you’ve been there before.
It also flattens the playing field. A freelancer or small IT consultancy with deep FOSS knowledge and homelab-built skills can compete with providers that charge ten times as much, simply by doing more with less. That’s a real business advantage, and it starts at home.
You Take Back Control of Your Data
Every service you self-host is a service you’re no longer depending on someone else to run, someone else’s servers to store your data on, and someone else’s pricing to change on you.
I run my own media server, my own photo library, my own document storage, my own password manager, my own DNS with ad-blocking, my own NVR for home cameras. None of these depend on a subscription. None of them will disappear because a company decided to shut down or pivot. None of them are sending my family’s data to a third party.
That’s not paranoia — it’s just a reasonable preference for owning the things you use every day.
Home Automation Gets Genuinely Useful
A homelab gives you the infrastructure to run Home Assistant properly — not the dumbed-down cloud version, but a real local instance with full control. When you combine that with the rest of your stack, things get interesting.
My Home Assistant is aware of everything on my network. It manages my UPS systems, monitors my servers, sends me alerts when something goes offline, and can automatically restart services when they misbehave. When my NVR node was crashing, Home Assistant detected the ping loss and cut and restored power via a smart plug to bring it back — automatically, at 3am, without me touching anything.
But what makes Home Assistant particularly powerful is that it speaks the language of virtually every smart home vendor out there. Zigbee devices, Z-Wave, MQTT, Tuya, Google, Apple, IKEA, Sonoff, Shelly — it doesn’t matter who made it, Home Assistant can integrate it. That means you’re not locked into a single ecosystem, you’re not dependent on any vendor’s cloud staying alive, and you can mix and match whatever hardware makes sense for your budget.
The automation side has real, measurable impact too. Lights that turn off when no one is in the room, climate control that adjusts based on presence, appliances that only run during off-peak hours — these aren’t just conveniences, they add up to meaningful savings on your electricity bill over time. You build them yourself, you understand exactly how they work, and you can tune them to your household’s actual patterns rather than relying on whatever a vendor’s app decides is “smart.”
And like everything else in the homelab, Home Assistant is a marketable skill. Small businesses, restaurants, offices — anyone with smart devices and no IT support has a problem you can solve. Setting up and managing a local Home Assistant instance, integrating their existing hardware, building automations that actually work reliably — that’s a service people will pay for, and it’s something you learn by running it at home first.
That’s not magic. It’s what happens when you have a proper homelab and take the time to connect the pieces.
The Cost Is Lower Than You Think
You do not need a server rack and enterprise hardware to start. The most useful nodes in my homelab are HP mini PCs that cost under $100 used. They’re compact, quiet, energy-efficient, and more than capable of running a handful of VMs or containers.
The honest costs are: hardware (low, buy used), electricity (low, small machines sip power), and time (the real investment). The time pays back in skills, income potential, and services you’d otherwise be paying subscriptions for.
Start with one machine. Install Proxmox or just plain Debian. Run one service. Break it. Fix it. Add another. That’s the entire playbook.
Where to Start
If you’re new to this, the barrier is lower than ever:
- Proxmox VE is free, installs on almost any x86 machine, and gives you a full hypervisor with a web UI. It’s where most serious homelabs begin.
- Old mini PCs (HP EliteDesk, Dell OptiPlex, Lenovo ThinkCentre) are ideal starter hardware — small, cheap, low power.
- Self-hosted services worth starting with: a DNS filter for ad-blocking, a reverse proxy for clean HTTPS access to your services, a self-hosted password manager, and a file sync solution.
- The community around homelabs is genuinely helpful — Reddit’s r/homelab and r/selfhosted are full of people at every level. YouTube is also an incredible resource: channels like Christian Lempa, Techno Tim, DBTech, and Craft Computing cover everything from beginner setups to advanced configurations, all with real demos and honest explanations.
- AI as your co-pilot — this is something I didn’t have when I started, and it changes the game completely. Before deploying anything, you can describe your idea to your AI of choice, walk through the architecture, catch the gotchas before they bite you, and get a second opinion on your approach. You’re not starting alone anymore. You can go from “I want to do X” to a working plan in minutes, then learn deeply as you actually build it.
The most important thing is to start. Don’t wait until you have the perfect hardware or the perfect plan. Stand something up, see what breaks, and go from there. The learning is in the doing.
The Honest Part
A homelab is not always fun. There are nights where something breaks at the wrong time, a service goes down that your household depends on, or a fix you were sure would work makes things worse. That’s part of it.
But those moments are also exactly why the homelab works as a learning environment. You’re motivated to fix it because you built it and you care about it. That motivation is the engine behind everything else.
I used to be a gamer. I still play occasionally — maybe five times a year — and I have nothing against it. But somewhere along the way I found that homelabing is more satisfying and enjoyable, honestly. There’s something about having fun while actually learning that hits differently. Every problem you solve, every service you deploy, every crash you diagnose and fix — it’s leveling up in real life. You’re not accumulating points in a game world, you’re accumulating skills and knowledge that carry over into everything you do professionally. That feeling is genuinely hard to replicate.
And then something interesting happens: you start sharing your services with friends and family. You give someone access to your media server, or set up your parents with a VPN, or share your media library with a relative. Without realizing it, you’ve become their service provider.
If what you provide is good, they’ll rely on it. And if they rely on it, they’ll complain when it breaks. That’s not a bad thing — it’s actually one of the best things that can happen to you. Suddenly you’re dealing with real users, real expectations, and real consequences for downtime. You start thinking about reliability, about backups, about graceful failure. You start solving problems that mirror exactly what happens in a professional environment, but in a context where the stakes are manageable and you have full control.
That combination — low stakes, real consequences, full ownership — is what makes a homelab irreplaceable as a learning environment. If you’ve been on the fence, consider this your push. Start small, break things, learn from it, and build something that’s genuinely yours.
Come to think about it, it is kind of fun.
The author runs a three-node Proxmox homelab in Panama, self-hosts most of his daily services, and has been building and breaking things at home for years.